

こんにちは、CCCMKホールディングス TECH LABの三浦です。
小さなころに体験したことの中で、なぜか今でもはっきり思い出せることがいくつかあります。自分にとってはその一つが"パンナ・コッタ"というお菓子を初めて食べた時の記憶です。"パンナ・コッタ"という独特な名前のせいなのか、味がとても美味しかったからなのか、理由は分からないのですが、その時のことを時々思い出します。
さて、最近Large Language Model(LLM)を使ったアプリケーションの開発のために色々とプロンプトの調整や処理パイプラインの工夫などを試しています。その中で試したことを細かく記録に付けていきたいな・・・と思っているものの、記録を付けるための仕組みを考えることに工数がかかったり、記録を付けるための手順が複雑で面倒になったり、チーム間で共有できなかったり、上手くシステム化出来ずにいました。
そんな中見つけたPhoenixというライブラリがとても使いやすく感じました。Jupyter Notebookから起動することが出来、一度起動しておけばLangChainで組んだLLMアプリケーションの実行結果を細かく記録してくれます。また、記録した入力と出力に対し、ハルシネーションが起きていないか検証を行う機能もあり、LLMアプリケーション開発のための試行錯誤にはもってこいだと感じました。
今回はこのPhoenixというライブラリについて紹介させて頂きます。
Phoenix
PhoenixはArize AIが開発しているAIのパフォーマンスの監視や評価を実現する、オープンソースのライブラリです。
ドキュメントがたくさんあり、Phoenixを使って色々なことが出来ることが伺えます。今回Phoenixを使ってみて大きく以下の3つに機能を集約できるのでは、と感じました。
- AIに対する入力と出力及びその中間処理の記録(Tracing)
- 記録された結果に対する評価(Evaluation)
- 画像やテキストデータの埋め込み表現の可視化(Inference)
ドキュメントを読んでいると、Retrieval-Augmented Generation(RAG)アプリケーションの監視や評価の用途で使用するExampleをよく見かけました。たしかに先述したTracing, Evaluation, InferenceどれもRAGに関連する機能なので、RAGの一連の処理を包括して扱うことが出来るライブラリと言えます。
PhoenixはAIアプリケーションの開発から運用までのステージをカバーすることが出来ます。今回はJupyter Notebookからローカル環境でPhoenixのサーバーを立ち上げましたが、サーバーで独立してPhoenixサーバーを立ち上げることも出来ます。
Jupyter Notebook環境でのPhoenixの利用
今回はJupyter Notebookを立ち上げ、そこからPhoenixを起動し、LangChainで構築したRAGのパイプラインに対する入出力の記録、記録に対するハルシネーションの評価までを試しています。
Phoenixのインストール
Phoenixのインストールはpipコマンドで行うことが出来ます。
pip install 'arize-phoenix[evals]'
今回はLangChainでRAGのパイプラインを組むため、LangChainやVectorDBのChromaもインストールしました。関連するライブラリのバージョンは次のように指定しています。
chromadb==0.4.24 langchain==0.1.16 langchain-chroma==0.1.0 langchain-openai==0.1.7
ポート
Phoenixのサーバーへは6006ポートで接続します。Dockerコンテナで動かす場合は6006を開放しておきます。
Phoenixの起動
Notebookを開き、セル内で次のコードを実行すると、Phoenixサーバーが起動します。
import phoenix as px from phoenix.trace.langchain import LangChainInstrumentor session = px.launch_app() LangChainInstrumentor().instrument()
LangChainInstrumentorによってこのNotebookで実行されるlangchainの処理が監視対象となり、ローカルで起動したPhoenixサーバーにログが送られるようになります。ここではLangChainを使用していますが、LlamaIndexなど、その他のライブラリに対応したInstrumentorも用意されています。
サーバーが起動すると、以下のメッセージが表示されるので、表示されているlocalhostのURLにアクセスすると、Phoenixの画面を見ることが出来ます。
🌍 To view the Phoenix app in your browser, visit http://localhost:6006/
起動しても、まだ何も処理を実行していないので空っぽの状態です。
LangChainによるRAGパイプラインの構築
次に観測対象になるRAGパイプラインを組んでいきます。前回Ragasを実行した時と同様にこのブログの記事の内容について答えてくれるRAGパイプラインです。前回と同じ内容なのでここでは割愛し、詳細はこちらの記事をご覧ください。
RAGの実行
RAGパイプラインをrag_chainという名前で作成し、Notebook内のセルで以下の様に実行します。
rag_chain.invoke({"question":"chainlitについて教えて"})
Notebookに結果として以下の様に表示されました。
'Chainlitは、対話AIや対話Agent型のアプリケーションをスピーディーに開発することができるPythonのフレームワークです。Chainlitにはさまざまな機能があり、LangChainやAutoGenといった別のLLM関連のフレームワークとも統合されています。また、Chainlitを使ってAzure OpenAI ServiceのChatGPTと対話ができるアプリケーションを作ることも可能です。\n\n具体的な使い方としては、Chainlitをインストールし、Chainlitの機能を使ってチャットアプリケーションを作成します。作成したアプリケーションでは、ユーザーからのメッセージを受け取り、Azure OpenAI ServiceのChatGPTを呼び出して応答を生成し、その応答を画面に表示します。\n\n参考情報には、Chainlitを使ってチャットアプリケーションを作成するための基本的な機能や設定方法が記載されています。具体的なコード例もありますので、詳細な使い方を知りたい場合は参考にしてください。'
続けてもう一つ実行します。
rag_chain.invoke({"question":"AutoGenについて要約して。"})
'AutoGenは、Multi-Agent Conversationを実装するためのフレームワークです。AutoGenのAgentは`ConversableAgent`クラスのサブクラスとして実装され、`send`、`receive`、`generate_reply`のメソッドを持っています。AutoGenには`AssistantAgent`と`UserProxyAgent`という2つの実装済みの`ConversableAgent`があります。`AssistantAgent`はAIアシスタントの役割を担い、LLMに基づいて行動します。一方、`UserProxyAgent`はユーザーの代理の役割を持ち、提案やコードをユーザーの代わりに実行し、その結果をAIアシスタントに伝える役割を担います。AutoGenでは、Agent間の会話を実現するために、"agent auto-reply"と呼ばれる機能があります。また、会話の制御は自然言語とPythonの両方で行うことができます。AutoGenはPythonのライブラリとして利用可能で、Dockerを使用して独立した環境で実行することもできます。'
Phoenixの画面を見てみます。

先ほどは空っぽだった画面に色々表示されています!このように一度PhoenixサーバーとInstrumentorを起動しておけば、Notebook内で実行した結果が自動的にPhoenixサーバに記録されます。とても便利だと思います!
Phoenixに記録された情報
Phoenixに記録された情報を見てみます。先に掲載した画面を見るとまずrag_chain.invokeを実行するたび、"Trace"という単位でデータが記録されていることが分かります。Traceごとにtotal token数やlatencyを確認することが出来ます。
Traceをクリックすると、次のようにさらに詳細を確認することが出来ます。

Traceを構成する最小処理単位をPhoenixでは"Span"と呼んでいます。

"Span"はPhoenixのクエリを使って様々な条件でNotebookから取得することが出来ます。この後この出力結果に対してハルシネーションの評価を実行するのですが、そのためにもまずNotebookからこの結果を取得する必要があります。
PhoenixのクエリによるSpanの抽出
Phoenixでハルシネーションの評価を行う場合、RAGへの入力(input)と回答(output)、それから検索された参考情報(reference)の情報が必要になります。これらの情報は複数のSpanにまたがっているため、それぞれPhoenixのクエリで抽出したのち、PandasのDataFrameとしての結合処理を実行し、評価のためのデータに仕上げます。
まずinputとoutputの情報を取得するためのクエリです。referenceと結合するための結合キーとしてtrace_idと評価結果をPhoenixサーバーに送る際に必要になるspan_idをcontext_span_idとして取得しておきます。
import pandas as pd from phoenix.trace.dsl import SpanQuery # このクエリはRAGに対するinputとoutputを取得するためのものです。 query_for_root_span = SpanQuery().where( "parent_id is None", ).select( trace_id="trace_id", context_span_id="span_id", input="input.value", # 入力 output="output.value", # 回答 )
次はreferenceを取得するためのクエリです。
# このクエリはRAGに対する参照情報を取得するためのものです。 query_for_retrieved_documents = SpanQuery().where( "span_kind == 'RETRIEVER'", # Filter for RETRIEVER span ).select( # Rename parent_id as span_id. This turns the parent_id # values into the index of the output dataframe. trace_id="trace_id", ).concat( "retrieval.documents", reference="document.content", )
この2つのクエリを実行し、PandasのDataFrameとして結合処理を行い評価用のデータに加工します。
# 2つのクエリの結果をJoinし、input, output, referenceを含むDataFrame形式にします。 evaluate_data = pd.merge( right = px.Client().query_spans( query_for_root_span ), left = px.Client().query_spans( query_for_retrieved_documents, ), on="context.trace_id", how="inner", ) evaluate_data = evaluate_data.set_index("context.trace_id") evaluate_data.head()
このようなデータになります。

ハルシネーションの評価の実行
先ほど作ったデータに対し、ハルシネーションの評価の実行を行います。ハルシネーションの評価判定にはGPT-4を使用しています。 このコードはPhoenixのドキュメントのものを使用しています。
from phoenix.evals import ( HALLUCINATION_PROMPT_RAILS_MAP, HALLUCINATION_PROMPT_TEMPLATE, OpenAIModel, download_benchmark_dataset, llm_classify, ) model = OpenAIModel( model="gpt-4", azure_endpoint=os.environ.get("AZURE_OPENAI_ENDPOINT"), api_key=os.environ.get("AZURE_OPENAI_API_KEY"), temperature=0.0 ) #The rails is used to hold the output to specific values based on the template #It will remove text such as ",,," or "..." #Will ensure the binary value expected from the template is returned rails = list(HALLUCINATION_PROMPT_RAILS_MAP.values()) hallucination_classifications = llm_classify( dataframe=evaluate_data, template=HALLUCINATION_PROMPT_TEMPLATE, model=model, rails=rails, provide_explanation=True, #optional to generate explanations for the value produced by the eval LLM )
このコードの実行結果であるhallucination_classificationsは以下のようなデータになります。

labelに評価結果、explanationに理由が出力されています。
Phoenixサーバーへの評価の記録
最後にこの評価の結果をPhoenixのサーバーに送信し、記録します。記録する際のデータの形式は、indexとしてcontext.span_idを持ち、labelとexplanationというカラムを持つPandasのDataFrameです。まずこの形式にデータを加工します。
result_df = pd.concat(
[
evaluate_data[["context_span_id"]],
hallucination_classifications
],
axis=1,
join="inner"
)
result_df = result_df.reset_index()
result_df = result_df.drop("context.trace_id",axis=1)
result_df = result_df.rename(columns={"context_span_id":"context.span_id"})
result_df = result_df.set_index("context.span_id")
result_dfを使って評価結果をローカルで稼働しているPhoenixサーバーに送ります。
from phoenix.trace import SpanEvaluations px.Client().log_evaluations( SpanEvaluations( dataframe=result_df, eval_name="Q&A Hullucination", ), )
Phoenixの画面で評価結果を確認することが出来るようになります。
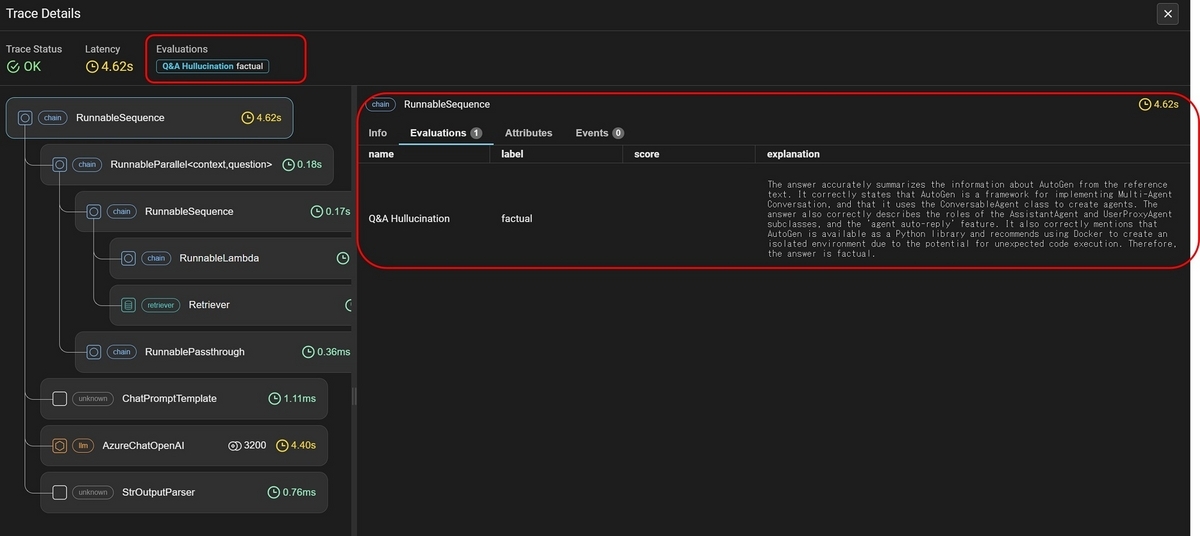
まとめ
今回はPhoenixというAIのパフォーマンスの監視や評価を行うことが出来るライブラリを使ってみた話をまとめてみました。Notebookの最初に数行コマンドを実行するだけですぐに記録を付けることが出来るようになるので、とても便利だと思いました。今回触れることが出来ていない機能はまだたくさんあるので、今後活用しながらまた別の機会にまとめてみたいと思います。